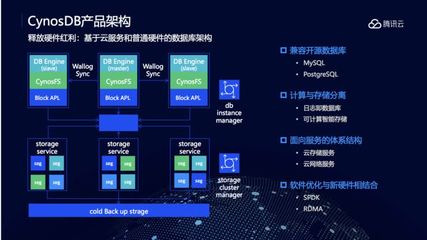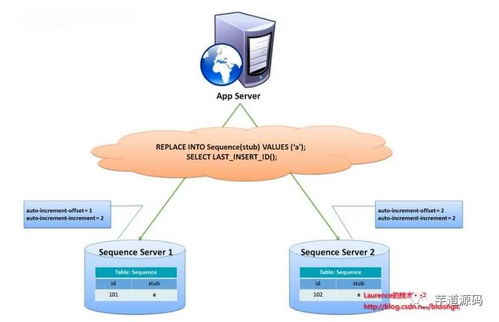
在數據庫優化過程中,分庫分表是常見的解決方案,用于應對數據量激增、讀寫性能瓶頸等問題。正如芋艿在CSDN博客中強調,盲目追求分庫分表而不考慮實際需求,可能導致復雜度和成本上升,反而得不償失。
分庫分表的核心目的是解決數據庫擴展性問題,但過早或過度拆分可能帶來管理困難。例如,跨庫查詢、分布式事務處理會增加開發難度和維護成本。如果數據規模尚未達到分庫分表的門檻,強行拆分只會讓系統變得臃腫。
分庫分表應基于業務場景進行決策。例如,高并發讀寫、海量數據存儲的場景下,拆分是必要的;但對于小型應用,單庫單表可能更高效。芋艿指出,開發者需評估數據增長趨勢、訪問模式和服務可用性,避免“為了分庫分表而分庫分表”的誤區。
分庫分表是工具而非目的。在數據庫服務設計中,我們應優先優化索引、緩存和SQL語句,再根據實際壓力逐步引入拆分策略。記住,技術服務于業務,理性選擇才能實現長期穩定。