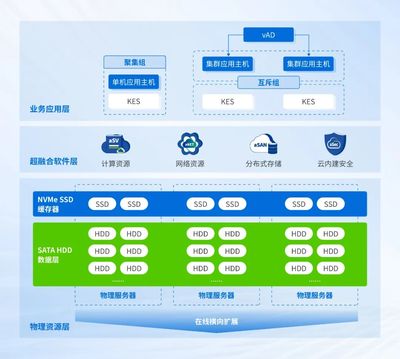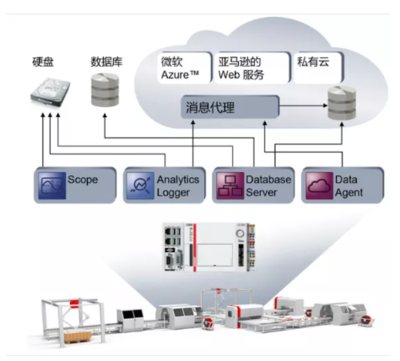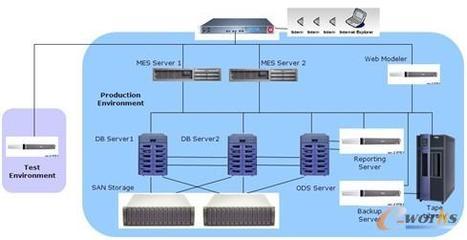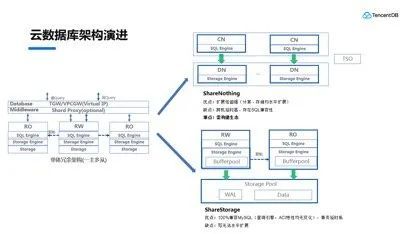
引言:當數據庫遇見無服務器
在云計算不斷演進的浪潮中,無服務器架構(Serverless)正從計算層向數據層延伸,引發了數據庫服務領域的深刻變革。無服務器數據庫并非指沒有服務器的數據庫,而是指一種新型的服務模式,它將底層服務器的管理、配置、擴展和維護工作完全交由云服務商處理,開發者只需按實際使用量付費,并專注于業務邏輯與數據模型的設計。
核心概念:無服務器數據庫的本質
無服務器數據庫的核心在于“按需供給”與“自動化管理”。它通常具備以下關鍵特征:
- 自動彈性伸縮:資源(如計算能力、內存、存儲)能夠根據負載實時、無縫地擴展或收縮,無需人工干預。在高并發時段自動擴容,在空閑時自動縮容至零或極低基線,從而優化成本。
- 按使用量計費:計費模式從傳統的預置容量(如購買固定的實例規格)轉變為按實際消耗的計算單元、存儲空間和數據傳輸量付費。這尤其適合流量波動大、難以預測的業務場景。
- 零運維管理:開發者無需關心服務器的操作系統、安全補丁、底層硬件故障或集群配置。服務提供商負責高可用性、備份、容災等所有運維復雜性。
- 內置高可用與全球分布:許多服務天生設計為多可用區甚至多區域部署,提供強一致或最終一致性的數據同步,保障服務的連續性與數據的持久性。
典型服務與架構模式
當前,主流云廠商均提供了代表性的無服務器數據庫產品:
- AWS Aurora Serverless / DynamoDB:Aurora Serverless 為關系型數據庫提供了自動伸縮的MySQL/PostgreSQL兼容服務;DynamoDB 則是全托管的NoSQL數據庫,其按需模式是無服務器理念的典范。
- Azure Cosmos DB Serverless:作為一個全球分布的多模型數據庫,其無服務器容器提供自動縮放和基于請求單元(RU)的消費定價。
- Google Cloud Firestore / Cloud Spanner:Firestore 是無服務器的文檔數據庫,專為移動和Web應用設計;Spanner 的實例配置也支持按需計算容量。
從架構上看,無服務器數據庫通常與事件驅動架構緊密結合。例如,通過數據庫的變更流(Change Data Capture, CDC)觸發無服務器計算函數(如AWS Lambda),實現實時的數據處理、分析或同步,構建完整的無服務器應用閉環。
核心優勢:為何選擇無服務器數據庫?
- 極致的成本效益:消除了閑置資源的浪費,僅為活躍工作負載付費。對于開發測試環境、初創項目或間歇性應用(如每月僅運行幾次的報告生成器),成本節省尤為顯著。
- 簡化開發與運維:大幅降低了數據庫管理的認知負荷和運維負擔,使小型團隊也能輕松駕馭復雜的數據基礎設施,加速產品上市時間。
- 無縫應對不確定性:能夠優雅地處理無法預測的流量高峰(如營銷活動、病毒式傳播),避免因容量規劃不足導致的性能瓶頸或服務中斷。
- 創新加速:開發者可以將更多精力投入到創造業務價值的應用邏輯上,而非底層基礎設施的“保姆式”維護。
面臨的挑戰與考量
盡管前景廣闊,但無服務器數據庫的采用也需謹慎評估其挑戰:
- 冷啟動延遲:當數據庫從“縮容至零”的狀態被請求喚醒時,可能需要數百毫秒甚至數秒的初始化時間(冷啟動),這對延遲敏感型應用可能不友好。不過,各服務商正在通過預置容量、保持連接池等技術不斷優化。
- 成本預測的復雜性:從固定成本變為可變成本,雖然總體可能更省,但月度賬單變得難以精確預測,需要精細的監控和成本分析工具。
- 功能與定制性限制:作為全托管服務,通常無法進行深度的底層調優或安裝自定義插件,可能無法滿足某些極端特殊的需求。
- 供應商鎖定風險:深度依賴特定云廠商的無服務器數據庫及其生態系統,可能導致遷移成本高昂。采用抽象層或多云策略可以部分緩解此問題。
- 數據模型與查詢適配:特別是對于無服務器NoSQL數據庫,需要精心設計數據模型和訪問模式以匹配其分布式特性,避免低效查詢產生高昂成本。
適用場景與最佳實踐
無服務器數據庫非常適合以下場景:
- 微服務與事件驅動應用:作為獨立微服務的專用數據庫,或事件處理流水線的一部分。
- 可變與不可預測的工作負載:如電商促銷、游戲新服開放、內容發布后的流量激增。
- 開發、測試與原型環境:按需啟動,用完即停,極大節約成本。
- 移動與Web后端:配合BaaS(后端即服務),快速構建應用。
最佳實踐包括:
- 精細監控與告警:密切關注請求量、消耗單元和成本指標。
- 設計彈性的數據訪問層:在應用中處理可能的冷啟動延遲或短暫故障。
- 優化數據模型與查詢:針對目標服務的特性進行設計,例如合理使用索引、避免全表掃描。
- 實施成本管控:設置預算和配額,防止因意外流量(如遭受攻擊)導致成本失控。
面向未來的數據基礎設施
無服務器數據庫代表了數據庫服務演進的明確方向——向著更自動化、更經濟、更以開發者為中心的模式發展。它并非傳統數據庫的替代品,而是在特定場景下極具競爭力的新選擇。隨著技術的成熟和生態的完善,冷啟動、成本預測等挑戰將逐步被攻克。對于企業和開發者而言,關鍵是根據自身應用的規模、穩定性要求、成本模型和技術棧,在“完全控制”與“極致便捷”之間做出明智的權衡,讓數據層的基礎設施真正成為業務創新的加速器,而非絆腳石。